Designing an AI Driven Sensitive Data Security Tool for Striim
Overview
In today's data-driven landscape, organizations process massive volumes of streaming data containing sensitive information such as personally identifiable information (PII), payment card data, social security numbers, and other regulated data types.
As data flows through real-time streaming pipelines, companies face a critical challenge: how to automatically discover, classify, and protect sensitive data in streaming data pipelines.
With Striim serving customers in the finance and healthcare sectors it was uniquely positioned to help prevent hefty fines by improving governance and security postures when moving data from source to target systems.

What is Striim ?
Striim is a platform for building data pipelines—connecting sources, transformations, and targets. Like a conveyor belt, it moves data between systems (such as databases and cloud services) in real time to power analytics and AI.
My Role
My Role: Lead UX Designer
Team: Product Manager, Engineering Team, User Researcher
Key Contributions: Design strategy, AI design patterns, interaction design, content design, visual design, user research consultation.
Research & Discovery
Background Research
As this feature encompassed two areas that were unfamiliar to me—sensitive data governance and AI—I started with extensive research. This included reviewing documentation, watching video tutorials on Data Security Posture Management and AI tools, and conducting a competitive analysis to establish our initial product vision.
User Research
We conducted interviews with customers in the financial sector to understand:
How organizations identify and classify sensitive data
Storage practices, user roles, and access levels
Breach implications and regulatory requirements
How Striim could enhance sensitive data handling
The Key Findings
Organizations struggle with these critical problems when handling sensitive data in streaming pipelines:
Invisible sensitive data - Limited visibility into what sensitive data exists within sources. This can pose a significant challenge if there are data quality issues.
Compliance risk - Potential violations of GDPR, CCPA, HIPAA, and PCI-DSS regulations. Companies must constantly adapt to regulatory changes.
Manual, inconsistent classification – Identifying and protecting sensitive data is time-consuming and error-prone. Organizations rely on a mix of industry standards and custom policies, with classification levels that vary by sector and region.
Poor handling of sensitive data leads to reputation loss, diminished client trust, and significant legal and financial consequences.
Usability Testing Approach
Due to tight timelines and limited customer access, we combined discovery research with usability testing during rapid design iterations.
Research Methods:
Structured interviews for initial insights and context
Think-aloud exercises with UI mockups for unbiased user perceptions
Modified desirability study using 34 positive/negative words to describe design feelings
This approach revealed customer feedback and uncovered previously unknown user needs.
A scenario for the desirability test

AI Design Strategy
My design approach was heavily influenced by Google's AI design guidelines, focusing on three key principles:
1. Help Users Calibrate Trust
Challenge: Users need to trust AI results without blind acceptance
Solution:
Communicate product capabilities and limitations upfront
Display privacy and security settings prominently
Include warnings about not blindly trusting results
Establish trust from the beginning and maintain it throughout the experience


2. Optimize for Understanding
Challenge: Users need to understand how AI classifications work
Solution:
Provide in-the-moment explanations of AI system functionality
Explain why the AI provided specific outputs
Use clear, comprehensive language for complex AI concepts


3. Manage Influence on User Decisions
Challenge: Users need to know when to trust system predictions
Solution: Display model confidence to help users make informed decisions
Key Design Innovation: Confidence Scoring
Through usability testing, we discovered users needed confidence scores to calibrate their trust in AI results. I spearheaded the initiative to implement this feature, working closely with engineering and product management.
Our Implementation:
Clear sample size display - Show the amount of data analyzed
Statistical confidence measure - For example: "Column A contains SSNs with 80% confidence based on analysis of 100 records where 80 contained SSNs"
This approach provided users with the context needed to make informed decisions about sensitive data classification.

The Designs
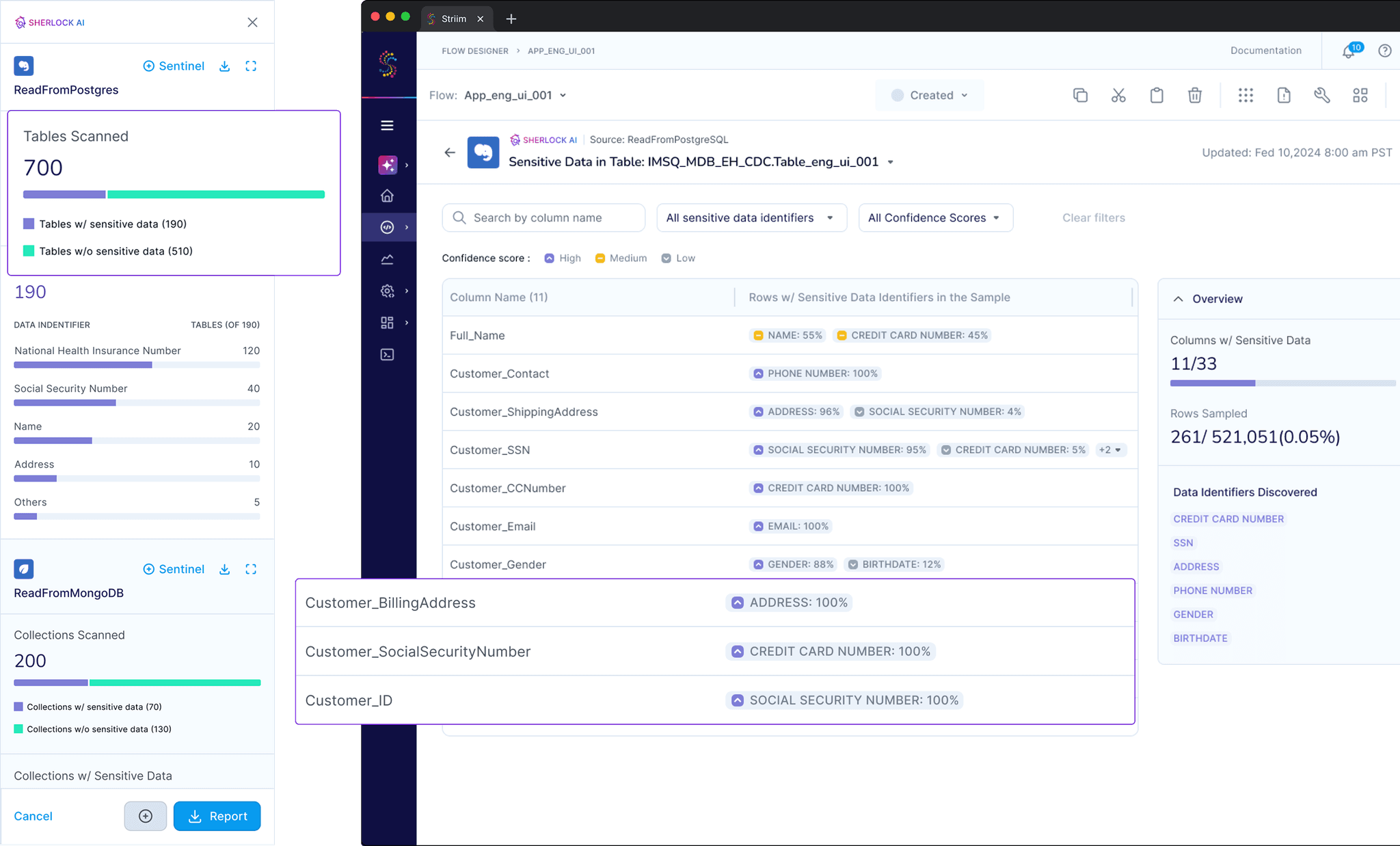
Sherlock: The Discovery Experience
User Story: As a Striim user with appropriate privileges, I want Striim to discover and report on the sensitive data that can flow into my pipeline from my data sources.
The discovery interface provides:
Automated scanning of sources in pipelines
Clear visualization of sensitive data findings
Confidence scores for each classification
Comprehensive reporting capabilities
Sentinel: The Protection Experience
User Story: As a Striim user with appropriate privileges, I want to protect the sensitive data that flows in my pipelines and use the sensitive data discovery report to do so.
The protection interface enables:
Policy-based data protection rules
Real-time masking and encryption options
Automated configuration based on the discovery findings
Use the discovery report to inform the pipeline design
Add a Sentinel that continuously detects sensitive data and protects it
Monitor the actions taken by Sentinel in real-time
Explanation of how Sentinel works (Source: Striim documentation)

Creative Constraints
Working within Striim's existing canvas experience and limited configuration panel space required creative solutions for complex data governance configurations while maintaining usability.
I took the opportunity to introduce a resizable configuration panel, allowing users to expand it and better focus on their configuration tasks. View my case study on how I reimagined the entire data pipeline creation experience here.
Search for a sensitive data category (identifier)
Adding (left) and removing (right) an identifier
Impact & Results
The AI-driven sensitive data discovery platform delivered significant value:
Business Impact:
Positioned Striim as an AI-forward platform in the data integration space
Provided customers with a competitive advantage in data governance
User Experience Impact:
Transformed complex compliance tasks into intuitive workflows
Increased user confidence through transparent AI decision-making
Reduced time-to-value for sensitive data protection implementation
Set the foundation for future user experience enhancements in the pipeline creation workflow.
Reflections
This project presented unique challenges that informed my approach to product design:
What I Learned:
Tight timelines require creative research methods - Combining discovery and usability testing was effective but required careful planning
AI design requires extra attention to trust-building - Users need confidence indicators and clear explanations to trust automated systems
Cross-functional alignment is crucial - When everyone is learning a new domain, clear communication and shared objectives become even more important
What I'd Do Differently:
If I were to revisit this project, I’d prioritize dedicated user research phases and establish clearer frameworks for cross-functional alignment—especially when working in unfamiliar technical domains. I’d also streamline the configuration experience by starting with a simple setup and introducing complexity gradually, based on user feedback, to avoid overwhelming users.
While there's room for improving both the UX process and final designs, this project was an invaluable learning experience in building AI-driven experiences. The tight constraints taught me to rapidly synthesize complex technical requirements into user-centered solutions and effectively communicate concepts to stakeholders.