Designing Automated Pipelines for Striim
A case study about learning from $925k in lost revenue and 6,000 support tickets in a year
Designed Striim's automated pipeline solution that reduced setup time from hours to minutes. Led design across three iterations, created the company's first design system, and the first iteration alone generated $500k revenue and processed 100TB of data in a month.
Striim builds data pipelines that move information between systems (databases, cloud services) in real-time to power analytics and AI.
Most customers need two things: Initial Load or IL (copy all existing data) followed by Change Data Capture or CDC(sync ongoing changes). Think automatic photo sync - take a one-time complete snapshot of your existing photos (IL), then every new photo automatically appears in the cloud in real-time (CDC). One setup, zero maintenance.
The gap: Despite supporting both of these use cases individually, Striim was missing a key experience: Automated Pipelines that managed the complete IL→CDC process
Staff Data Engineer
Potential customer
"Overall Striim does have the features that we're looking for but there's quite a sizable manual work to maintain both the initial historical load and the CDC part. We decided to go with another solution."
The damage: $925k+ in lost revenue. 179 critical issues. 6,000 support tickets from botched manual setups over a year.
The root cause: Every customer needed our support team to manually coordinate Initial Load (copying existing data) and CDC (syncing ongoing changes) - a complex, error-prone process that was killing our growth.
The manual pipeline setup requires users to create and coordinate separate IL and CDC pipelines, exposing complex configurations that overwhelm SMB users and drive support ticket volume.
This project spanned three major iterations over several years, with my role evolving as the team structure changed.
V1: Sole designer
V2: Part of a 2-person team responsible for the configuration experience
V3: Returned to solo design responsibilities as we integrated the automation features into the main platform.
Design System Foundation: Pitched and designed Striim's first design system, now implemented throughout the entire product ecosystem. This foundation significantly accelerated subsequent design iterations across all Striim products.
Standalone Product Success: As sole designer, created a new product from scratch that generated $500k in revenue and processed 100TB of data in a month.
SMB-Focused Innovation: Designed Striim's first guided experience specifically for data engineers at small-to-medium businesses, transforming a technically complex enterprise process into an accessible self-service workflow.
A snapshot from the first iteration of the design system

Competitive Analysis: Analyzed wizard-like experiences from Qlik, Fivetran, Attunity, Amazon Glue, HVR, and Airbyte to understand industry standards for automated data pipeline creation.
User Research: Conducted interviews with internal data engineers as well as with consultants hired by Striim to understand pain points in the current manual process and validate design directions through usability testing.
What started as a database migration tool evolved through three iterations, each teaching us that great design needs the right business strategy to succeed.
V1: StreamShift - The Proof of Concept
Competitive Analysis: Analyzed wizard-like experiences from Qlik, Fivetran, Attunity, Amazon Glue, HVR, and Airbyte to understand industry standards for automated data pipeline creation.
User Research: Conducted interviews with internal data engineers as well as with consultants hired by Striim to understand pain points in the current manual process and validate design directions through usability testing.
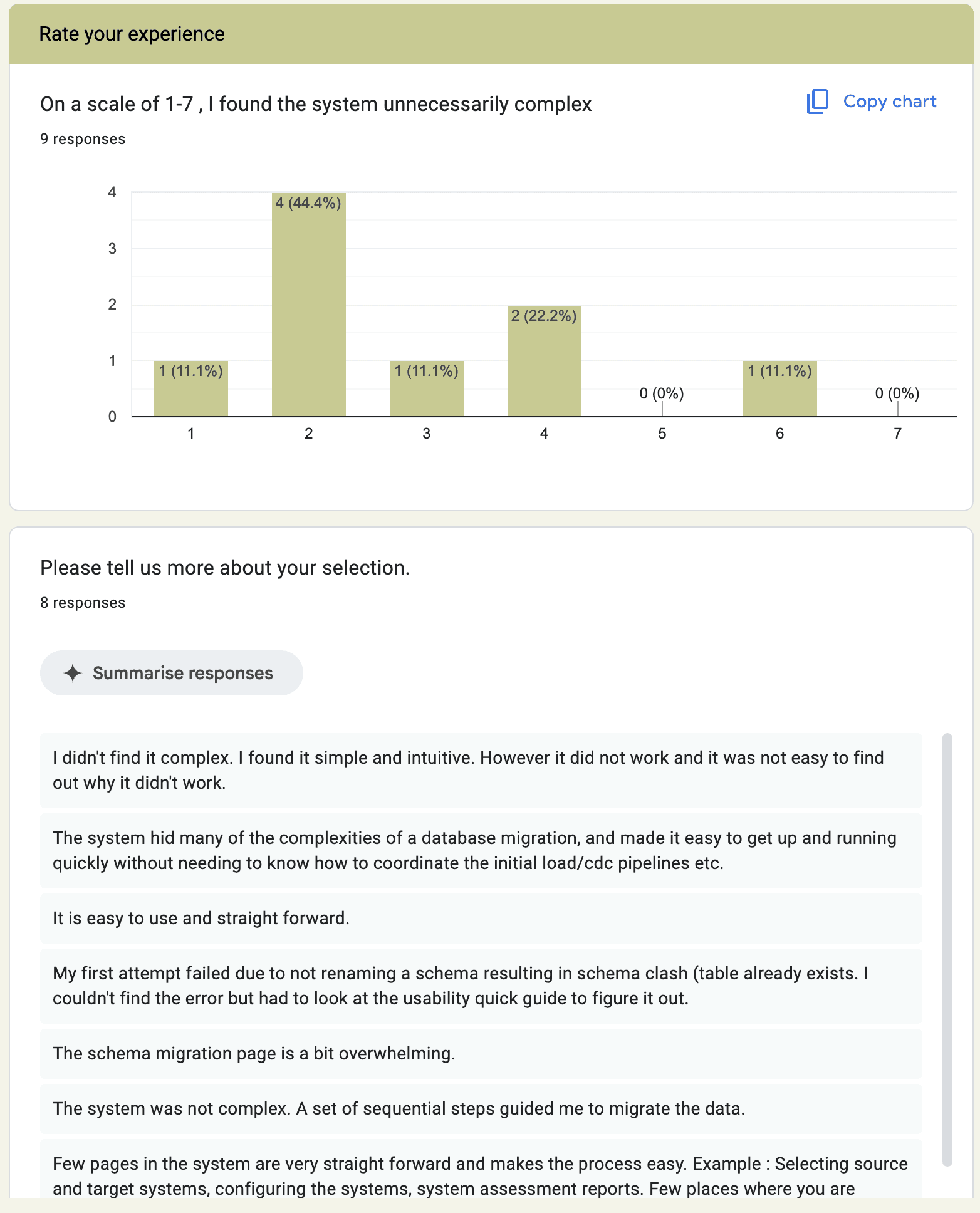
Responses to a question from the post-task questionnaire.
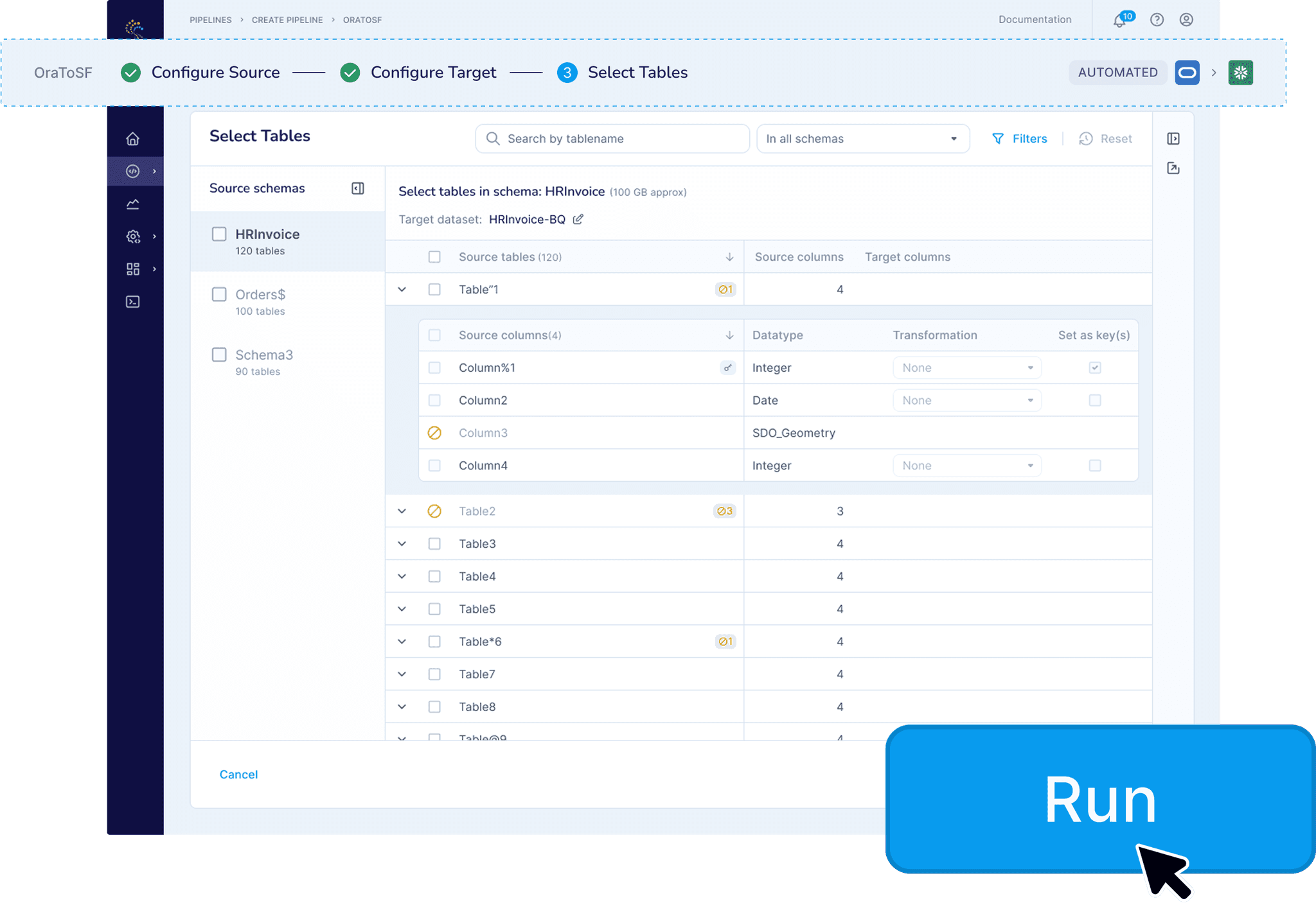
V2: BigQuery Focus - Following the Money
BigQuery represented 60% of Striim's revenue but was not supported by V1. We evolved the product to help users move their data dedicatedly to Google BigQuery as part of our partnership with Google.

Designs
Step 1: Configure the Target

Step 2: Configure the Source
Step 3: Select the Data to Move

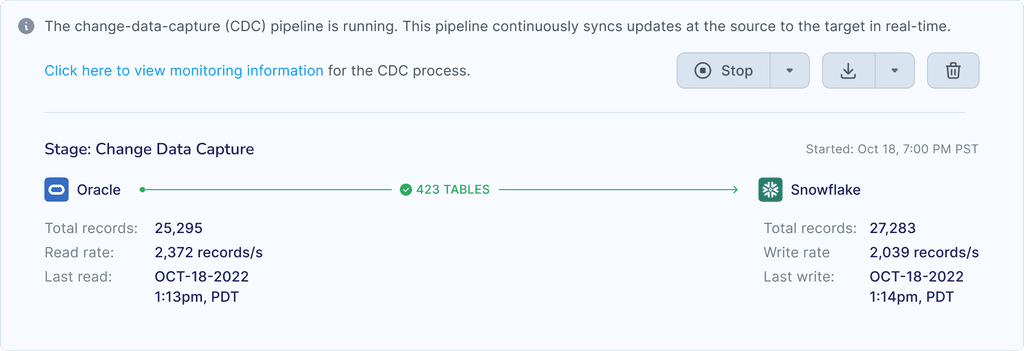
Step 4: Monitor

Collaborative design effort between myself and the other designer showing live data flow progress and system health metrics during the IL-to-CDC transition process.
Validation
Internal testing with data engineers and external consultants helped validate the simplified experience and eliminate major pain points. The final product was tried by around 300 potential customers, but resulted in no business revenue.
Excerpts from the usability test sessions I conducted to validate the designs.

The Unraveling
Instead of integrating automation into our main platform, leadership launched V1 and V2 as a separate product.
The UX was headed in the right direction. The business strategy was catastrophic.
Market Confusion: ~10 Striim products suddenly existed. Customers couldn't choose. Sales team was overwhelmed.
Pricing Death Spiral: 4x more expensive than signing up for the storage solutions.
Feature Gaps: Missing 100+ connectors, transformations, and enterprise features that existed in our main product.
The Killer Blow: Existing customers started churning because they wanted automation, but it was only available in a separate product (with feature gaps).

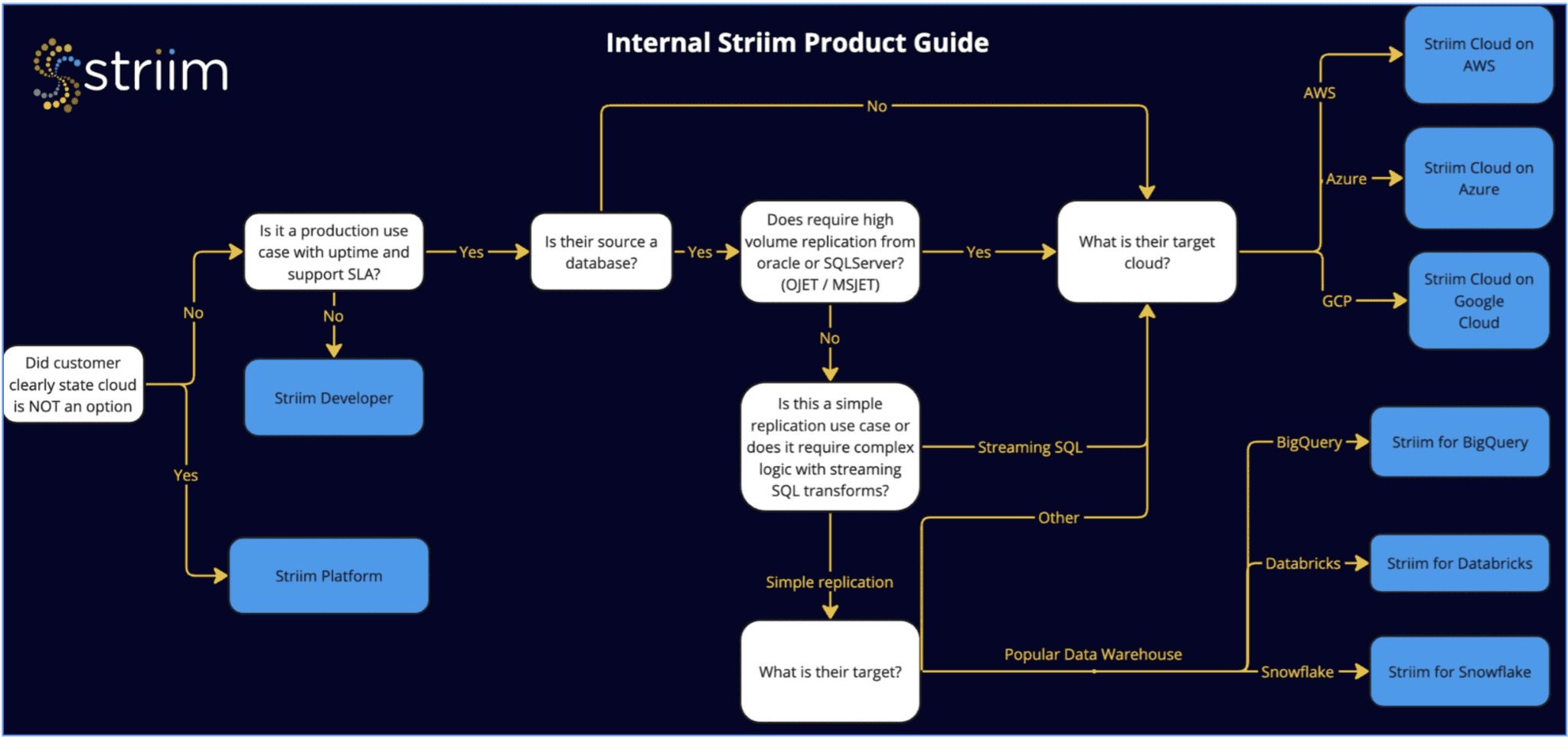
V3: Reuniting the Products
The separate product failed within 18 months. We integrated automation back into Striim Enterprise, where it belongs.
An exploration of user flows and information architecture